Today I have sent an email to give my opinion about a service and to ask the service provider to consider an improvement.
When I was just about to send it I wondered if the receiver could have been able, if interested in what I have written, to do a lookup up of my mail address and find the pages that represent me better since the address is the one I use in formal communication.
As pages that represent me I mean stuff like my Facebook, Google+, LinkedIn pages, in my case.
And since my email was in the form of "NAME.SURNAME@gmail.com" , a typical standard if you are lucky enough to find it available when you create an email account with a specific provider, I was expecting it to work properly.
So I performed a test and I have browsed for my official email address in Google search, and to try limit as much as possible, all the tracking informations that my browser could send or remember, I performed my test with an instance of Firefox in Private Mode.
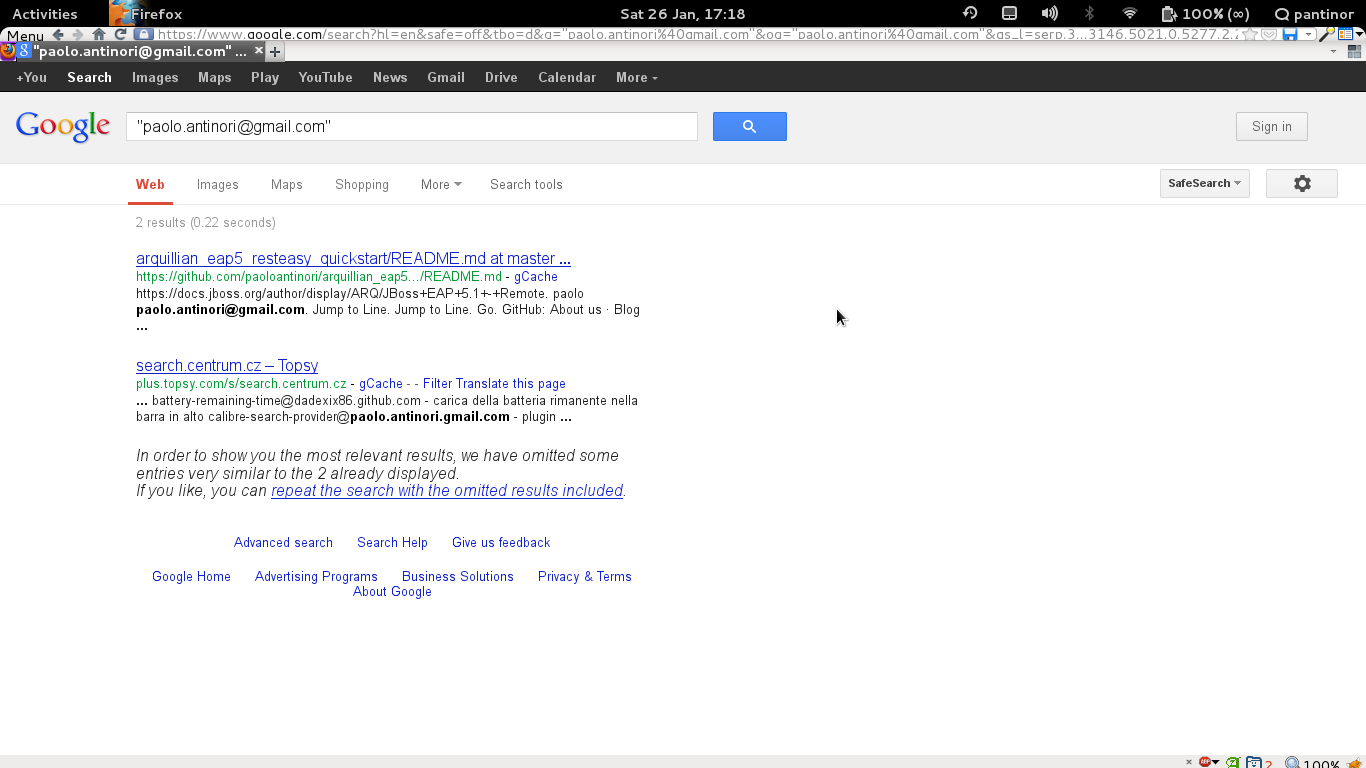
And the result turned to be interesting:
Google identified me correctly... for the first 4 results:
- It finds one of my projects on GitHub
- It finds my national LinkedIn page
- It finds me on LinkedIn.com
- It finds my Google+ Page

But it screws it completely for the rest of the first result page links:

For what I have seen from those links, yes, I can say that both my name and my surname, taken independetly are present in the results, but not only I have nothing to do with those pages, but my original query, my NAME.SURNAME@gmail.com email is not there at all and they are not even listing my omonimous.
The pages are not even including the NAME.SURNAME string, that I could expect it may exists as the username chosen by any of my omonimous that could have open an account with providers other than Gmail.
Instead no, the logic that I can guess is that the Google algorithm has not identified my query as an email address and looked just for that.
This behaviour is not completely surprising, since I can expect that the "Did you mean?" functionality could be based on some soundex algorithm or eventually on other statistics and metrics, but the suggested pages are not containing any evident variation of my email address.
It seems to me that email addresses are searched just like any other query on Google and no particular optimization is applied to them. This is definitely surprising, considering the many optimizations or even easter eggs that we can find in the engine:
Try to search for "Apple stock", "1 eur in dollar" or pay attention to the suggested correction when trying to search for "recursion".
I am a software engineer but not an expert in search engines at all, so I do not know if the problem that I am describing is crazy complex or not, but from a user point of view, I do believe that a very common use case is not correctly managed by the search engine.
I know that Search Engine Optimization is a discipline on its own, but my use case is much simpler I think.
From a smart search engine I would expect that if search for an email, the engine would be able to automatically try to look for just the sequence of characters that I have put in the search bar.
Eventually I'd like to receive some suggestion for eventual typos if the system does not find results. I could also accepts suggestion based on similar words, but still in the context of email addresses not just in the the body of other pages.
From a smarter search engine I would expect it to guess that a TOKEN1.TOKEN2 would lead the engine to at least give priority to the option that TOKEN1 could be my name and TOKEN2 could be my surname, and eventually enforce its opinion based of some statistic that could prove that TOKEN1 is indeed a common first name.
I'm saying it again. I really have no clue how doable this idea is, but I do believe that it should not be much harder than now when parts of my search results are correct and others are instead very unrelated to search.
Other interesting considerations based only on my single test:
- Google finds a page with my full email on Github, because it was on a README text file that I have uploaded there, but it's not suggesting my profile page that still shows publicly my email address.
- Google+, that also has my official mail public, it's only fourth
- the ninth result, that is a YouTube page, finds a post of one omonimous of mine.
- when I searched Google passing my email enclosed by quotes, I receive only 2 results back: the same GitHub page and a scam page.